AWS에서 무중단 배포, 스케일링 적용 후기
2025.12.08
이 포스팅은 클라우드 인프라 구축을 설명하는 글이 아닌 후기 입니다.
AWS에서 오토 스케일링과 무중단 배포를 적용해본 후기
지난 면접 후기 포스팅에서 말한것 처럼 클라우드 운영의 부족한점을 채우기위해 직접 클라우드 환경을 구축해보고 테스트 해보기로했고 그 결과를 포스팅으로 작성한다.
테스트 환경 구축하기
무중단 배포와 스케일링을 적용하기위해선 먼저 실제 프로덕션과 유사한 클라우드 환경부터 먼저 구축해야했다. 간단하게 rds + ec2 인스턴스에 nest.js로 백엔드를 실행중인 환경을 가정하고 구축했다.
내가 구축한 전체 환경은 아래와 같다.
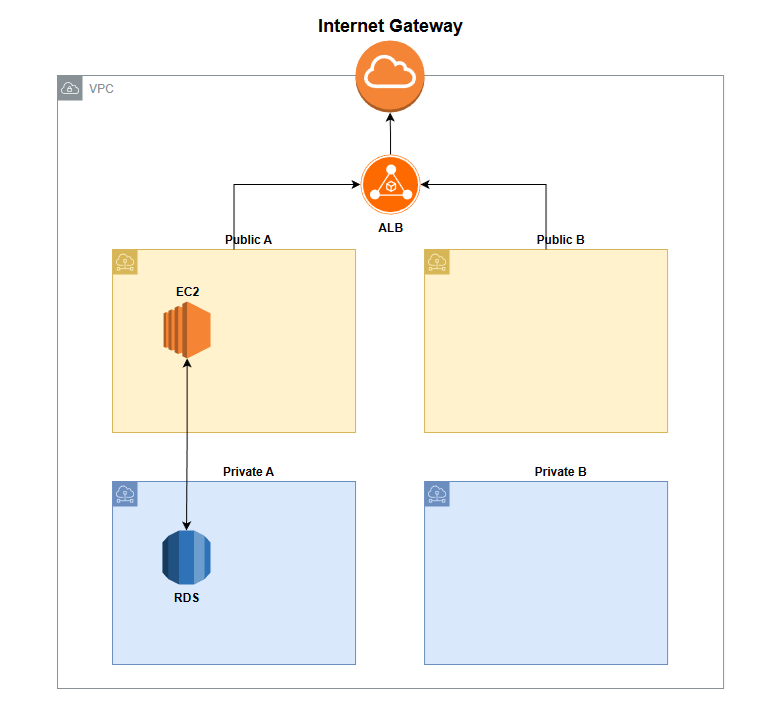
- VPC 내부에 서로다른 AZ에 Public/Private 서브넷이 각각 1개씩 있다.
- RDS는 단일 인스턴스로 Private 서브넷 안에 있다.
- Nest.js가 실행되는 ec2는 Public 서브넷에 있다.
- ALB를 통해 ec2의 CPU 사용량을 감시하고 스케일링이 적용된다.
EC2 구성
실제 nest.js 백엔드가 실행되는 서버 역할을 한다. 여기에 nest.js가 실행되는 환경을 구축해야하는데 내가 클라우드를 처음 접했을때는 직접 인스턴스에 접속해서 패키지를 설치하고 github에서 코드를 pull하는등 실행환경을 구축하는 방식으로 했었지만 이번에는 이런거 말고 좀더 제대로 해보고싶은 마음도 있었고 가장 큰 이유는 그냥 귀찮아서 지금 내 로컬에서 테스트하던 nest.js 환경을 그대로 도커 컨테이너로 만들어서 그냥 ec2에서 그대로 실행시키고 싶었다.
특히 오토스케일링을 적용시키려면 새로운 인스턴스를 생성할때도 기존의 인스턴스와 똑같은 환경을 만들어야하기때문에 사실상 도커를 사용하는것이 필수였다.
그래서 도커만 설치하고 실행되는 ec2환경을 구성하고 이걸 AMI 이미지로 만들고 이 이미지로 인스턴스를 실행하고 도커 이미지만 pull 받아서 그대로 실행시키는 방법은 어떨까하고 생각했고 내가 구성한 ec2 환경은 아래와 같다.
- nest.js 실행환경은 도커 이미지로 빌드하고 ecr에 업로드
- 도커만 설치된 인스턴스를 AMI로 이미지화
- 위 이미지로 인스턴스를 실행하면 자동으로 실행되는 스크립트로(User Data) ecr에 있는 도커 이미지를 받아서 그대로 실행
RDS 구성
이번 테스트는 db관련 테스트가 아니라 간단하게 단일 인스턴스 하나만 사용했다.
하지만 prisma ORM을 사용했는데 db 스키마를 rds에 초기화하는 작업이 필요했다.
로컬에서 처음 부터 개발할때는 문제가 없었지만 이미 개발이 완료된 스키마를 새로운 rds에 어떻게 적용해야할지 몰랐다.
특히나 rds는 외부에서는 아예 접근이 불가능한데 그렇다고 bastion 호스트까지 구축하기엔 너무 과하다고 생각해서 이번에는 그냥 rds를 초기화할때만 외부접속을 허용시키고 로컬에서 접속하여 초기화를 시킨다음 바로 외부접속을 차단하는식으로 했다.
다소 아쉬웠던 부분이지만 이건 나중에 학습해보기로하고 넘어갔다.
백엔드 구성
실제 테스트에 사용할 nest.js 백엔드 서버가 필요하다.
실제 db가 정상적으로 동작하는지도 확인하기위해 간단하게 get과 post 두개만 구성했다.
import { Injectable } from '@nestjs/common';
import { PrismaService } from 'prisma/prisma.service';
import * as crypto from 'crypto'; // Node.js 내장 모듈
@Injectable()
export class AppService {
constructor(private prisma: PrismaService) {}
async getHello() {
const [count, latest] = await Promise.all([
this.prisma.log.count(),
this.prisma.log.findMany({
take: 10,
orderBy: {
createdAt: 'desc',
},
}),
]);
return {
count,
latest,
message: 'Hello World! V1',
};
}
async createHello() {
this.stressCpu(1000);
await this.prisma.log.create({
data: {},
});
return 'Hello Created! V1';
}
private stressCpu(iterations: number) {
for (let i = 0; i < iterations; i++) {
crypto.pbkdf2('secret', 'salt', 100, 64, 'sha512', () => {});
//참고: 이 코드는 원래 pbkdf2Sync() 였다 자세한 내용은 아래에서 후술한다
}
}
}
단순하게 create와 find만 하기엔 실제 스케일링이 제대로 작동하는지 확인할수가 없기때문에 의도적으로 cpu를 많이 사용하는 코드를 적용했다.
orm으로 prisma를 사용했는데 이건 진짜 매번 새로운 프로젝트에서 쓸때마다 버전이 바뀌는것 같다.
이번에도 7버전으로 업데이트되면서 세팅 방식이 완전히 달라졌다. 다행이 prisma 공식문서에 nest.js에 적용하는 튜토리얼이 있었다.
로컬에서는 아무 문제없이 동작하는걸 확인하고 이를 도커 이미지로 빌드하고 ecr에 푸시했다.
ALB 구성
테스트에 필요한 핵심인 alb를 구성하고 ec2를 감시하는 그룹(Target Group)에 등록했다.
모든 트래픽은 alb에 의해서 분배된다.
테스트 환경을 테스트하기
본격적으로 스케일링과 무중단배포를 적용하기전에 지금의 구성이 제대로 동작하는지부터 확인해야했다.
그래서 직접 ec2 하나를 실행시키고 alb의 주소로 접속하니 정상적인 응답과 db도 제대로 돌아가고있는것을 확인했다.
ASG 적용하기
위에서 구성한 인프라에 asg를 적용했다.
cpu 사용율이 50% 이상일때 스케일링이 되도록 지정하고 인스턴스 갯수는 최소 1대에서 최대 2대를, 시작 템플릿으로 위에서 만들어둔 ami으로 인스턴스를 생성하고 시작 스크립트(User Data)를 통해 ecr에서 도커 이미지를 pull 받고 실행시키도록 설정했고 alb에 등록했던 tg를 연결했다.
이제 asg의 설정에 따라서 tg에 실행중인 인스턴스가 없다면 자동으로 새로운 인스턴스를 실행시키며 시작 템플릿에따라 도커를 통해 백엔드 서버를 실행한다. 또한 인스턴스 새로고침 이라는 기능으로 백엔드의 새로운 버전이 배포되었을때 무중단으로 적용시킬수 있다.
테스트와 결과
asg까지 적용하고나서 테스트를위해 수동으로 띄워두었던 인스턴스를 삭제했다.
asg의 설정대로 새로운 인스턴스가 자동으로 생성되었고 문제없이 서버도 실행되었다.
이제 대망의 부하 테스트와 무중단 배포 테스트를 할 차례다.
부하 테스트에는 k6 라는 도구를 사용했다. (npm에 있어서 패키지 같은건줄 알았는데 알고보니 프로그램이라서 설치를 해야하더라 그래서 그냥 k6도 도커로 씀)
import http from 'k6/http';
import { check, sleep } from 'k6';
export let options = {
stages: [
{ duration: '1m', target: 50 }, // 1분 동안 동시 접속자 50명까지 증가
{ duration: '5m', target: 50 }, // 5분 동안 유지
{ duration: '1m', target: 0 }, // 1분 동안 0명으로 감소
],
};
export default function () {
// ALB 주소 입력
let res = http.post(
'ALB 주소',
);
check(res, { 'status was 200': (r) => r.status == 200 });
sleep(1);
}
간단한 테스트 코드를 작성한다. 주석대로 정해진 시간동안 끊임없이 alb로 요청을 보내는 코드고 이로인해 인스턴스에 부하가 감지되면 자동으로 새로운 인스턴스를 띄울것이다.
k6를 실행시키기전에 실제 부하를 눈으로 확인하기위해 aws에 있는 모니터링 탭은 전부다 열어두고 만반의 준비를했다.
부하 테스트
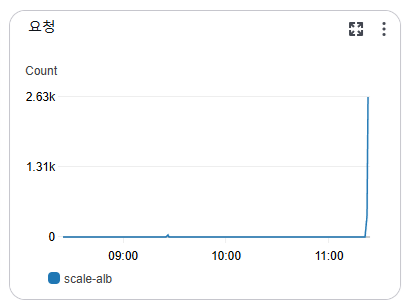
k6를 실행시키고 잠시후 실제로 alb에 트래픽이 늘어나는게 감지되었다.
ec2의 cpu 점유율도 지속적으로 확인했지만 딜레이가 있어서 확인을 못하고있었다.
그와중 브라우저로 직접 접속하여 새로고침 하면서 서버가 계속 살아있는지 체크했다.


갑자기 브라우저로 접속한 페이지에서는 503 에러가 뜨고 k6 로그에서도 실패가뜨며 alb에서는 인스턴스 헬스체크가 실패하는등 여기저기서 문제가 터져나왔다.
어찌된 일인지 ai에게 분석을 요청했더니 스케일링이 동작하기도전에 서버가 먼저 터져버린것 같다고 대답했다.
private stressCpu(iterations: number) {
for (let i = 0; i < iterations; i++) {
crypto.pbkdf2('secret', 'salt', 100, 64, 'sha512', () => {});
}
}
실제 백엔드에서 쓰는 부하용 코드인데 사실 이 코드는 수정된 버전이고 원래 는 crypto.pbkdf2Sync() 였다.
이게 동기식으로 동작하면서 nodejs의 싱글스레드 특성상 이 cpu집약 작업(반복문)이 끝날때까지 블락이 생긴다. 실제로 부하 테스트를 하기전에 테스트했을땐 응답에 평균 1초 정도가 걸렸었다.
문제는 이 1초가 걸리는 응답에 동시에 수십명이 몰리다 보니까 응답을 다 처리하지 못하고 503 에러가 발생했으며 cpu 점유율이 50%가 넘기도전에 alb의 헬스체크도 실패해서 서버가 터진걸로 판단이 된것이었다.
의도치 않은 Dos 공격을 날리는 사소하고 앙증맞은 찐빠가 있어서 첫번째 테스트는 실패했다.
나중에 ec2가 안정되고나서 ec2의 로그를 살펴보니 실제로 피크때 cpu 점유율이 48%로 50%를 넘기지 못했었다. 그래서 백엔드의 코드를 수정해서 부하가 좀 덜 걸리도록 수정해야 했었다.
솔직히 말하면 부하 테스트만 해보려고했는데 마침 코드를 업데이트 해야하는 상황이 발생해서 이참에 무중단 배포도 테스트를 하기로했다.
무중단 배포 테스트
방법은 정말 간단했다. ecr에 업데이트된 이미지를 push하고 asg에서 인스턴스 새로고침 이라는걸 실행하면 끝이었다.
asg가 알아서 새로운 인스턴스를 생성하고 (업데이트된 백엔드 이미지 실행) 이 인스턴스의 헬스체크가 통과될때까지는 기존의 인스턴스를 그대로 사용하고 새로운 인스턴스가 문제가 없다고 판단되면 기존의 인스턴스를 종료시킨다. 이 과정이 무중단 업데이트 다.
다만 실제 프로덕션이라면 당연히 자동화가 되어있겠지만 이번에는 이것이 제대로 동작하느냐를 확인하는것이 목적이었기때문에 직접 실행했다.
이걸 실행하기전에도 실제로 무중단으로 업데이트가 적용되는지 확인하기위해 k6를 실행시켜놓은 상태에서 진행했다. 추가적으로 구분을 위해서 백엔드의 코드도 Hello World! V1 에서 Hello World! V2 로 수정했다.
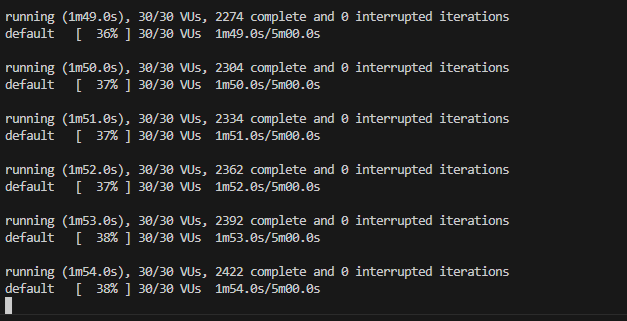
k6로 get 요청을 계속 확인하는 상태에서
 인스턴스 새로 고침이 실행되었다. 인스턴스가 새로 만들어지고 있는게 대시보드에 보였다.
그리고 브라우저에서도 계속 새로고침하면서 응답을 체크했다.
결과는 성공적이었다. 새로고침을 계속 하던중 응답이 바뀌는걸 눈으로 확인했다.
{
"count": 431,
"latest": [
{
"id": "b3562e88-8971-4128-9605-0939d4fdea7d",
"createdAt": "2025-12-03T11:34:39.311Z",
"updatedAt": "2025-12-03T11:34:39.311Z"
},
//...
{
"id": "749a525b-c226-4d81-a548-3347459a7497",
"createdAt": "2025-12-03T11:34:31.311Z",
"updatedAt": "2025-12-03T11:34:31.311Z"
}
],
"message": "Hello World! V1" // 주목
}
이게 기존 V1 에서의 응답이었고
{
"count": 431,
"latest": [
{
"id": "b3562e88-8971-4128-9605-0939d4fdea7d",
"createdAt": "2025-12-03T11:34:39.311Z",
"updatedAt": "2025-12-03T11:34:39.311Z"
},
//...
{
"id": "749a525b-c226-4d81-a548-3347459a7497",
"createdAt": "2025-12-03T11:34:31.311Z",
"updatedAt": "2025-12-03T11:34:31.311Z"
}
],
"message": "Hello World! V2" // 주목
}
이게 실제 V2의 응답이었다. 그리고 이 과정이 진행되는 동안에도 k6는 계속 실행중이었는데 테스트가 끝나고 k6의 결과에서도 응답 실패는 0건 이었다.
무중단 업데이트가 성공적으로 반영된것이다.
부하 테스트 (2트)
업데이트가 반영된것을 확인하고 다시 k6를 통해서 부하 테스트를 진행했다.
이번에는 부하 강도를 줄여서 실행했는데 확실히 503에러는 뜨지 않았다.
잠시후 실행중인 인스턴스의 cpu 부하가 50% 이상을 찍는것을 확인했다. 그리고
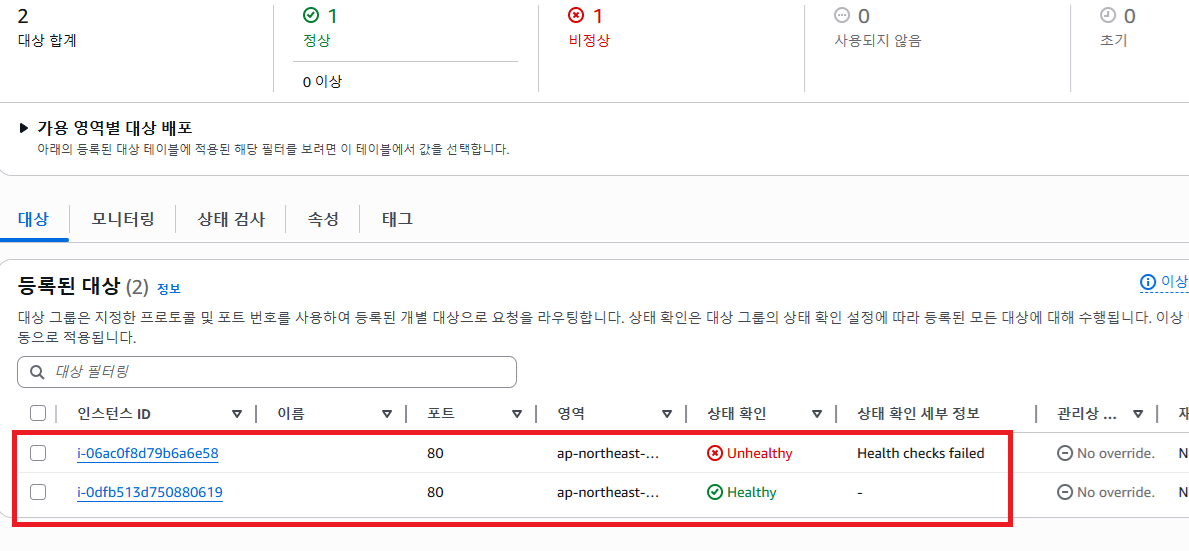
새로운 인스턴스가 생성되고 실행준비중인게 alb에서 관측됐다.
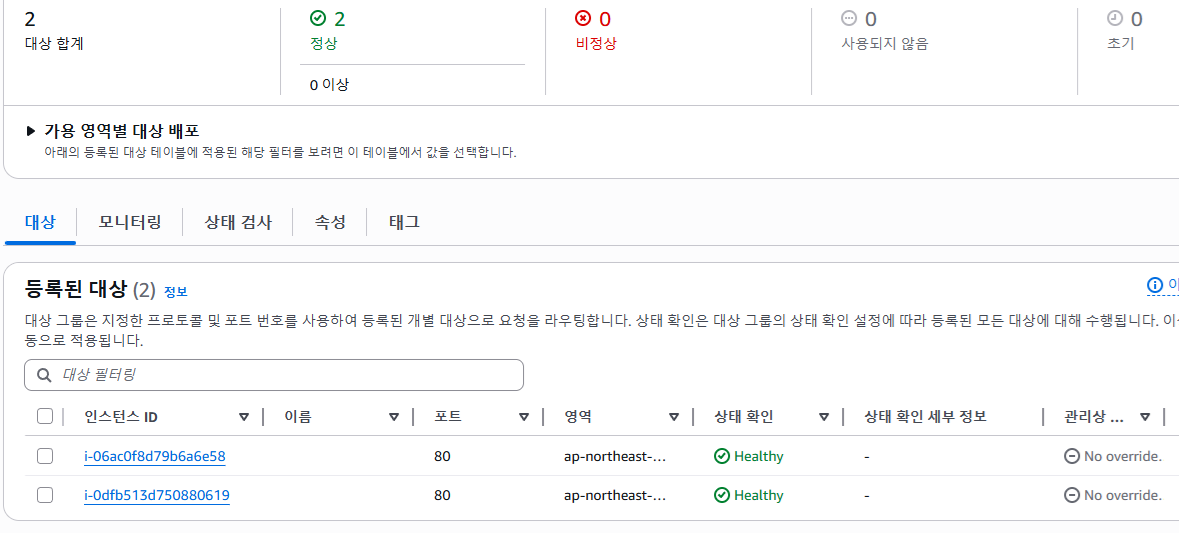
또 잠시후 실행된 인스턴스도 헬스체크가 완료되고 2개의 인스턴스가 성공적으로 실행되고있는것을 확인했다.
마지막으로 k6 테스트가 종료되고나서 대략 20분정도 지났을때
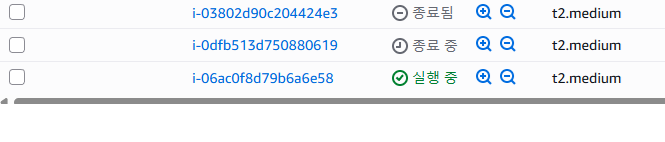 인스턴스하나를 종료시키고 다시 1대로 돌아가는것까지 확인했다.
인스턴스하나를 종료시키고 다시 1대로 돌아가는것까지 확인했다.
결과적으로 부하 테스트도 성공적이었다.
후기
 (수많은 테스트의 흔적들)
(수많은 테스트의 흔적들)
이번 테스트로 꽤나 많은것들을 배우고 경험할수있었다.
지난 면접에서 느낀 아쉬움이었던 들어는 봤지만 해본적은 없는 것들을 몸소 체험했다.
클라우드 인프라를 구성할때 이 방법 말고도 AWS ECS나 쿠버네티스같은 선택지가 있다.
실제로 내가 테스트한 이 구성을 ai에게 전반적으로 평가를 해달라고 했을때
기초적(classic) 이지만 현업에서도 실제로 쓰는방식이고 충분히 좋은 방식이다. 여기서 더 발전된 형태가 ECS이나 쿠버네티스 다.
라고 평가했다.
사실 처음부터 ecs이나 쿠버네티스로 바로 시작할수도 있었지만 난 개인적으로 이렇게 기초적인 형태를 직접 경험해보면서 원리를 파악하는걸 선호하는 편이라 기초를 충분히 익히고 나서 다음 단계로 쿠버네티스로 넘어가자 라고 생각했다.
이제 기초를 다졌으니 계획대로 다음번엔 쿠버네티스를 배워야겠다.